
Hosting
Skalowanie ruchu HTTP
Co znajdziesz w tym artykule:
Sezonowość sprzedaży i nagłe skoki ruchu na stronie to wyzwania branży e-commerce. Odpowiedzią na problemy z wydajnością może być właściwie dobrany typ usługi serwerowej. Black Friday lub Cyber Monday jest najlepszą okazją na wykorzystanie zasobów dostępnych na żądanie w środowisku chmury. Skutecznym sposobem na zwiększenie możliwości przyjęcia dużego ruchu przez serwis jest skalowanie architektury. Istnieje kilka sposobów skalowania, które znacząco zwiększają możliwości przyjęcia większego obciążenia.
HTTP Gateway
HTTP gateway jest znane pod pojęciem reverse proxy. Przyjmuje połączenia od urządzeń użytkownika – klientów – serwisu internetowego, a następnie przekazuje zapytania do innych serwerów znajdujących się w tzw. backend, serwujących kod serwisu. Kiedy otrzyma odpowiedź, HTTP gateway zwraca ją do klienta.
Wiele stron ma prostą budowę, na jednym serwerze fizycznym znajduje się serwer HTTP który uruchamia kod aplikacji oraz serwuje pliki statyczne. Dodatkowo znajduje się tam też baza danych aplikacji. Konfiguracja taka nie jest dość optymalna i ma swoje limity, związane z wydajnością maszyny i jakością kodu.
Dziesiątki tysięcy połączeń
Każda nowa sesja http z przeglądarki otwiera od 6 do 8 połączeń do serwera, jeżeli głównym serwerem HTTP jest Apache może się okazać że podczas takiego połączenia zaalokowana zostaje duża ilość pamięci serwera. W przypadku kilku tysięcy użytkowników online, otwierane są dziesiątki tysięcy połączeń.
Może to doprowadzić do wyczerpania zasobów pamięci serwera, w konsekwencji do przeniesienia operacji z pamięci na dysk, co może w znaczący sposób spowolnić operacje. Jeżeli liczba połączeń będzie się zwiększać proces ten w konsekwencji może dotykać znacznej części użytkowników. Ostatecznie może dojść do wyczerpania limitów połączeń serwera oraz wyczerpania zasobów CPU co w przypadku użytkownika końcowego objawia się bardzo wolnym działaniem strony lub jej całkowitą niedostępnością.
Jednym z rozwiązań pozwalającym zapobiegnąć tym problemom oraz umożliwiającym skalowanie jest reverse proxy HTTP gateway. Obsługę ruchu od użytkowników przejmuje serwer reverse proxy, który przesyła zapytania do serwerów HTTP w backend. Serwery w backed mogą pracować z pełną wydajnością, obsługując tylko kilka sesji do serwera reverse proxy.
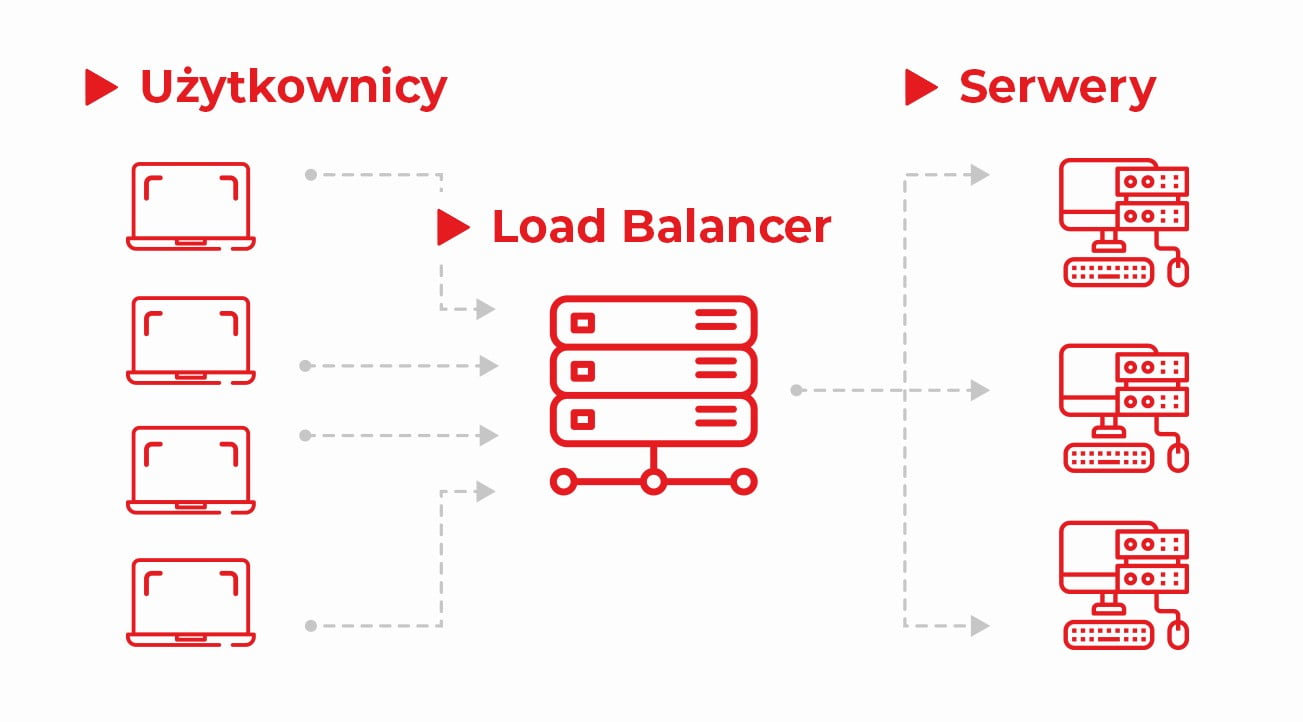
Serwer reverse proxy może spełniać funkcje
- loadbalancera (rozłożenie ruchu http na kilka maszyn/instancji serwera apache),
- cache (HTTP gateway może kierować ruch do statycznych plików do lokalnego cache lub zewnętrznego systemu cache),
- akcelerator SSL,
- limitowanie ruchu.
Reverse proxy serwer może przyspieszyć działanie strony nawet w przypadku gdy posiadamy 1 serwer aplikacji. Przejmuje on obsługę ruchu z internetu i może działać jako cache. To pierwszy etap rozbudowy infrastruktury w celu osiągnięcia większej wydajności i możliwości obsługi większego ruchu. Jest to też 1 krok do budowy bardziej zaawansowanych systemów. Następnym etapem jest wdrożenie większej ilości serwerów aplikacji, tak aby rozłożyć obciążenie pomiędzy kilka instancji serwerów czy to fizycznych czy wirtualnych.
Rozważając rozłożenie obciążenia pomiędzy kilka instancji trzeba zwrócić uwagę na każdy z elementów ponieważ, każdy z nich musi posiadać odpowiednie zasoby by nie stał się tzw. „słabym ogniwem” które spowolni działanie całego systemu.
Round robin na dobry początek
Potrzebna jest też odpowiednia strategia balansowania ruchu pomiędzy serwery znajdujące się w backend. Najprostszą strategią jest round robin. Bardziej zaawansowane metody uwzględniają obciążenie serwerów w backend i wysyłają żądania do mniej obciążonych serwerów. Bardzo istotną sprawą jest kierowanie klientów do tych samych serwerów w backend w obrębie jednej sesji oraz monitorowanie obciążenia.
Zaawansowane metody load balancing
Bardziej zaawansowane metody load balancingu potrafią uruchomić/zatrzymywać dodatkowe „uśpione” instancje serwerów w backend np. w środowisku chmury. Mogą to być serwery wirtualne, kontenery lub też same serwery fizyczne, tak aby bez problemu obsłużyć szczytowe obciążenie, tylko w czasie jego wystąpienia.
Dodatkowe funkcje jakie oferuje reverse proxy:
- cache elementów serwisu,
- terminacja połączeń SSL,
- terminacja HTTP/2
To dość istotne funkcje, które pozwolą rozbudować/skalować system w przyszłości i pozwolić na obsłużenie większego obciążenia.
Limitowanie ruchu
Typowy ruch od użytkownika jest przewidywalny, długość i ilość sesji inicjowanych przez przeglądarkę jest możliwa do oszacowania. Jednakże w przypadku robotów skanujących strony, które to są automatami ruch taki może znacznie obciążyć serwer gdzie nakładając na to ruch normalnych użytkowników może dojść do wysycenia zasobów. W przypadku specjalnych wydarzeń kiedy spodziewamy się większego ruchu możemy potraktować ruch z robotów/automatów inaczej niż ruch normalnego użytkownika. Taką funkcję może również realizować reverse-proxy, tj. limitować ruch z automatów skanujących, przez limitowanie ilości połączeń na sekundę z 1 adresu IP oraz ilość transferowanych danych.
Dodatkowo należy też zadbać o ochronę przed atakami DDoS.
Poczytaj więcej na naszym blogu
-
Korzyści posiadania własnego adresu IP
Posiadanie własnego adresu IP staję się coraz trudniejsze. Wyczerpana pula adresów przez RIPE NCC sprawia, że coraz częściej użytkownicy samodzielnie poszukują możliwości jego pozyskania. -
Przyśpieszenie strony dzięki konwersji zdjęć na WebP
Przyspieszenie ładowania się stron www to oczko w głowie tak wielu specjalizacji (SEO, UX, CRO, PPC), że nic dziwnego co chwila pojawiają się nowe sposoby […]